

Advancing Self-Driving Cars with Reinforcement and Imitation Learning
Advancing Self-Driving Cars with Reinforcement and Imitation Learning
How machines could handle the infamous unprotected left turn like a human, and more

Measuring Progress
Last week, what felt like the whole self-driving car industry shared their thinking on how we should measure the progress in autonomous driving:
I can confirm that many companies in the industry struggle with disengagements as the gold-standard measure, in large part because the press uses this metric to rank each project every year (and does so erroneously from time-to-time). The aforementioned companies are likely tiring of the yearly cycle, but without proposing an alternative metric to report publicly, they will likely have to suffer from reporting disengagements for the foreseeable future.


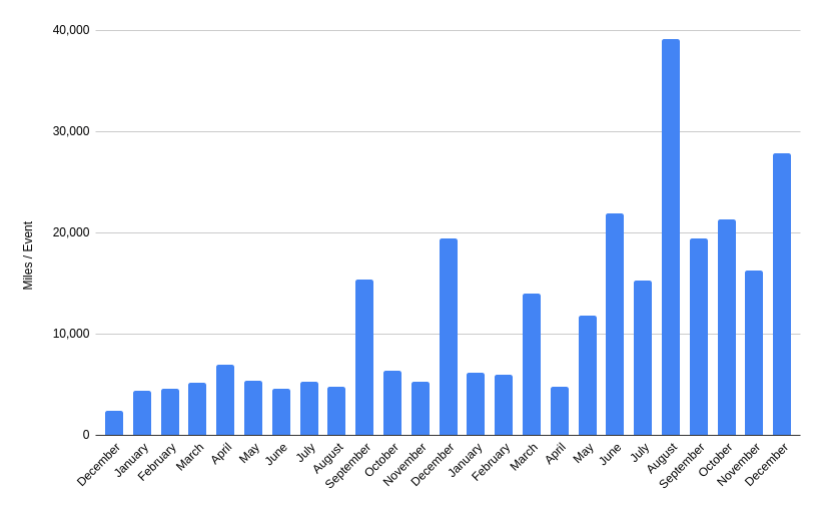
Ironically, what stood out to me most from this set of blog posts was Cruise’s 2019 disengagement numbers. Although an outlier, in August 2019 Cruise reported only a single DMV-reportable disengagement after almost 40,000 miles of San Francisco driving. For reference, in 2018 Cruise posted an average of 1 disengagement every 5,200 miles of driving, with Waymo leading after reporting an average of 1 disengagement every 11,000 miles.
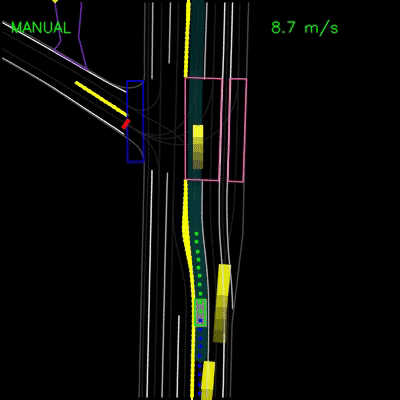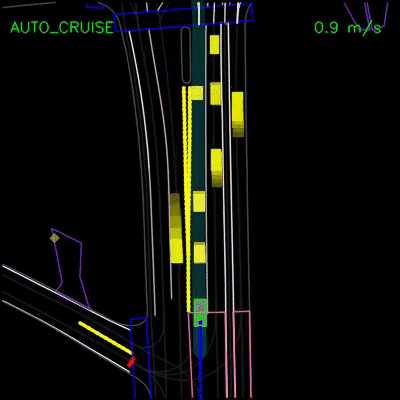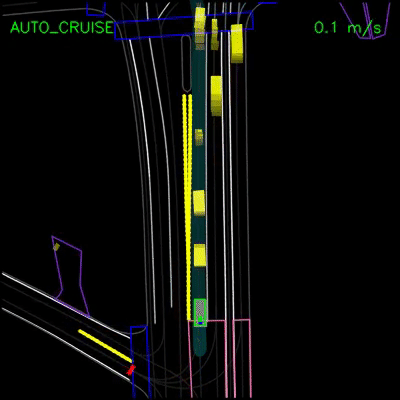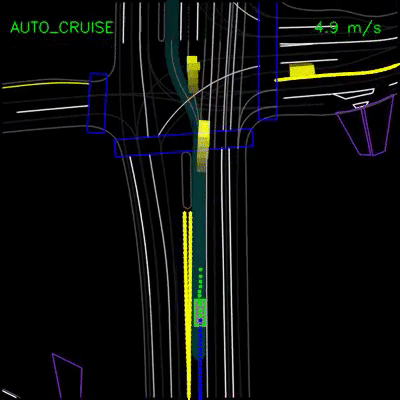
The Infamous Unprotected Left Turn

The unprotected left turn: a demonstration of the most difficult aspects of autonomous driving. The self-driving car must carefully, yet swiftly, navigate across lanes of oncoming traffic while acting in tandem with other fast-paced, dynamic agents. Making a wrong decision at an unprotected left creates at best awkward encounters, and at worst severe safety concerns.
The problem of prediction is central to the most difficult instantiations of the unprotected left turn. A self-driving car must predict the future actions of all the dynamic agents around it before it executes the turn, a task that requires significantly more intelligence than other problems in autonomous driving. Human drivers, albeit not perfect, lean heavily on general intelligence, real-world driving experience, and social cues (such as nudging or hand-signals), to successfully execute unprotected left turns.

Although machines have clear advantages over humans (e.g. 360° long-range vision), traditional prediction within self-driving technology can be, by comparison to humans, quite primitive:
Your perception module outputs a set of object detections (e.g. vehicles, pedestrians) within a certain radius of the self-driving car, which is then fed into your prediction module
Your prediction module uses present (e.g. orientation, speed) and previous observations to generate individual predictions about what each object may do in the next 5 seconds
By feeding all of these individual predictions into an algorithm, a hypothesis can be generated about the safest action the self-driving car can execute
The self-driving begins the prescribed maneuver and re-assesses the decision every 100 milliseconds
What’s missing in the above module is any concept of “experience”. The prediction module, under identical circumstances, will output the same set of (potentially incorrect) predictions on drive #1 as drive #10,000. Although this approach can generate impressive and safe interactions, it often results in a self-driving car that is overly cautious when compared to a human driver, especially in dense, urban environments. For passengers, this means longer trip times and uncomfortable, robotic maneuvers.

At Voyage, we are enthusiastic about Reinforcement Learning and Imitation Learning techniques to solve these “experience” deficits, ultimately resulting in a less robotic ride for passengers.
The output of Reinforcement Learning (RL) or Imitation Learning (IL) models is learned from previous driving experience, whether by granting rewards for successful navigation (RL) or from comprehensive, labeled driving datasets (IL). We started Voyage Deepdrive to create an environment to safely test these techniques and push the state-of-the-art in self-driving artificial intelligence. Deepdrive’s first-class support for RL and IL means that researchers can focus solely on the problem of driving, rather than worrying about the stack required to run their agents on a physical car.
When deployed mid-to-end (meaning post-perception), RL and IL models offer a potentially significant advantage over traditional autonomous driving techniques, in that they do not rely on brittle, robotic predictions in order to drive. Rather, RL and IL models infer the correct driving action to execute from prior, real-world experiences. Such models have been trained on tens of thousands of roadway scenarios (think 10-second snippets of driving), which enable the self-driving car to use past experiences to solve the present scenario. Over time, with more data and learnings, RL and IL models will only improve. How these models handle drive #10,000 will be far superior to drive #1.
Reinforcement Learning and Imitation Learning has shown tremendous promise in other complex tasks, but we are still early in the application of it within self-driving cars. Voyage is not alone in making a bet on these techniques, with companies like Wayve, Ghost, and Waymo (see ChauffuerNet) actively researching this problem area.
Tesla Fully Self-Driving Video
The Tesla recruiting team recently shared a new video of Tesla’s Fully Self-Driving (FSD) technology in action. On the surface the video is impressive, and Elon Musk definitely has reason to be excited about it. That said, as the industry knows all too well, it’s relatively trivial to record a video where everything works perfectly for a limited time, and it’s far more complex to repeat those same maneuvers over thousands of miles in multiple locations. That said, I look forward to seeing more of Tesla’s FSD progress.

That’s all for this week. Please send any feedback or thoughts via Twitter, and be sure to tell any friends hungry for self-driving car knowledge to subscribe.
